인접 참조를 링크해서 체인처럼 관리, 앞뒤로 서로의 링크를 참조한다. (특정 인덱스에서 인스턴스를 제거하거나 추가하게 되면 바로 앞/뒤 링크만 변경하면 되기 때문에 인스터스 삭제와 삽입이 빈번하게 일어나는 곳에서는 ArrayList보다 성능이 뛰어남)
Application1
import java.util.*;
import java.util.ArrayList;
import java.util.Collection;
import java.util.Date;
import java.util.List;
public class Application1 {
public static void main(String[] args) {
/* List 인터페이스를 구현한 모든 클래스는 요소의 저장 순서가 유지되며,
* 중복 저장을 허용한다.
* ArrayList, LinkedList, Vector, Stack이 있다.
*
* */
/* ArrayList
* 가장 많이 사용되는 컬렉션 클래스이다.
* JDK 1.2부터 제공된다.
* 내부적으로 배열을 이용하여 요소를 관리하며, 인덱스를 이용해
* 배열요소게 빠르게 접근할 수 있다.
*
* ArrayList는 배열의 단점을 보완하기 위해 만들어졌다.
* 배열은 크기를 변결할 수 없고, 요소의 추가, 삭제, 정렬들이 복잡
* 하다는 단점을 가지고 있다.
*
* ArrayList는 크기변경 (새로운 더 큰 배열을 만들고 데이터 옮기기)
* , 요소의 추가, 삭제, 정렬기능등을 미리 메소드로 구현해서 제공하고있다.
* 자동적으로 수행되는 것이지 속도가 빨라지는 것은 아니다.
*
* */
/* ArrayList는 인스턴스를 생성하게 되면 내부적으로 10칸까지
* 배열을 생성해서 관리한다.
* */
ArrayList alist = new ArrayList();
/* 다형성을 적용하여 상위 레퍼런스로 ArrayList 객체를 만들수도 있다.
* ArrayList는 List인터페이스를 상속받기 때문이다.
* List인터페이스 하위의 다양한 구현체들로 타입변경이 가능하기 때문에
* 레퍼런스 타입은 List로 해 두는 것이 더 유연한 코드를 작성하는 것이다.
* */
List list = new ArrayList();
/* 더 상위 타입인 Collection 타입을 사용할 수도 있다.
* Collection 타입은 Array 와 List의 상위타입이기 때문
* */
Collection clist = new ArrayList();
/* ArrayList는 저장 순번이 유지되며 index(순번)이 적용된다.
* ArrayList는 Object 클래스의 하위타입 인스턴스를 모두
* 저장할 수 있다. */
alist.add("apple"); //String
alist.add(123); //int
// 객체만 저장가능, autoBoxing 처리해서 기본자료형들을 자동으로 변환 해준다.
alist.add(45.67); //double
alist.add(new Date());
/* toString 메소드가 오버라이딩 되어있다.
* 출력 해 보면 저장 순서를 유지하고 있다.
* */
System.out.println("alist : " + alist);
// alist : [apple, 123, 45.67, Mon Jan 10 10:23:25 KST 2022]
/* size()메소드는 배열의 크기가 아닌 요소의 갯수를 반환한다.
* 내부적으로 관리되는 배열의 사이즈는 외부에서 알 필요가 없기
* 때문에 기능을 제공하지 않는다. */
System.out.println("alist의 size : " + alist.size());
// alist의 size : 4
/* 내부 배열에 인덱스가 지정되어 있기 때문에 for문으로 접근 가능하다. */
for (int i = 0; i < alist.size(); i++) {
/* 인덱스에 해당하는 값을 가져올 때는 get(인덱스전달값)
* 메소드를 사용한다. */
System.out.println(i + " : " + alist.get(i));
}
// 0 : apple
// 1 : 123
// 2 : 45.67
// 3 : Mon Jan 10 10:25:35 KST 2022
/* ArrayList는 데이터의 중복 저장을 허용한다.
* 배열과 같이 인덱스로 요소들을 관리하기 때문에 인덱스가
* 다른 위치에 동일한 값을 저장하는 것이 가능하다.
* */
alist.add("apple"); // apple 인덱스를 추가한다.
System.out.println("alist : " + alist);
// alist : [apple, 123, 45.67, Mon Jan 10 10:26:59 KST 2022, apple]
/* 원하는 인덱스 위치에 값을 추가할 수도 있다.
* 값을 중간에 추가하는 경우 인덱스 위치에 덮어쓰는 것이 아니고
* 새로운 값이 들어가는 인덱스 위치에 값을 넣고 이후 인덱스는
* 하나씩 뒤로 밀리게 된다.
* */
alist.add(1, "banana");
System.out.println("alist : " + alist);
// alist : [apple, banana, 123, 45.67, Mon Jan 10 10:28:58 KST 2022, apple]
/* 지정된 값을 삭제할 때는 remove() 메소드를 사용한다.
* 중간 인덱스의 값을 삭제하는 경우 자동으로 인덱스를 하나씩 앞으로 당긴다.
* */
alist.remove(2);
System.out.println("alist : " + alist);
// alist : [apple, banana, 45.67, Mon Jan 10 10:31:04 KST 2022, apple]
/* 지정된 위치의 값을 수정할 때에도 인덱스를 활용할 수 있으며
* set() 메소드를 사용한다.
* */
alist.set(1, true);
System.out.println("alist : " + alist);
// alist : [apple, true, 45.67, Mon Jan 10 10:32:00 KST 2022, apple]
/* 코드 작성중 노란줄이 많이가는 이유?
* : 모든 컬렉션 프레임 워크 클래스는 제네릭 클래스로 작성 돼 있다. */
List<String> stringList = new ArrayList<>(); // 타입 추론이 가능하기에 생략 가능
/* 스트링 타입만 저장하는 객체이다, 라는 의미 */
/* 제네릭 타입을 지정하면 지정한 타입 외의 인스턴스는 저장하지 못한다. */
stringList.add("apple");
//stringList.add(123); // int 타입은 컴파일 에러
stringList.add("banana");
stringList.add("orange");
stringList.add("mango");
stringList.add("grape");
System.out.println("stringList : " + stringList);
// stringList : [apple, banana, orange, mango, grape]
/* 저장 순서를 유지하고 있는 stringList를 오름차순 정렬해보자 */
/* Collection 인터페이스가 아닌 Collections 클래스이다.
* Collection 에서 사용되는 기능들을 static 메소드로 구현한 클래스이며
* 인터페이스명 뒤에 s가 붙은 클래스들은 관례상 비슷한 방식으로 작성 된 클래스를 의미하게 된다.
* */
Collections.sort(stringList);
/* sort 메소드를 사용하면 list가 오름차순 정렬 처리 된 후 정렬 상태가 유지된다.
* 즉, 원본에 영향을 미친다.
* */
System.out.println("stringList : " + stringList);
// stringList : [apple, banana, grape, mango, orange] // 오름차순정렬
/* 조금 복잡하지만 내림차순 정렬을 할 수도 있다.
* 하지만 기본적으로 ArrayList에는 역순으로 정렬하는 기능은 제공되지않는다.
* 역순 정렬은 LinkedList에 정의되어있는데 현재 사용하는 ArrayList를
* LinkedList로 변경할 수 있다. 둘다 Collection을 상속받고 있다.
* */
stringList = new LinkedList<>(stringList); //arrayList -> LinkedList
/* Iterator 반복자 인터페이스를 활용해서 역순으로 정렬한다.
* 제네릭 적용하는 것이 좋다.
* LinkedList 타입으로 형변환 한 후 descendingIterator()메소드를 사용하면
* 내림차순으로 정렬 된 Iterator 타입의 목록으로 반환해준다.
*
* Iterator란?
* Collection 인터페이스의 Iterator() 메소드를 이용해서 인스턴스를 생성할 수 있다.
* 컬렉션에서 값을 읽어오는 방식을 통일된 방식으로 제공하기 위해서 사용한다.
* 반복자라고 불리우며 반복문을 이용해서 목록을 하나씩 꺼내는 방식으로 사용하기 위함이다.
* 인덱스로 관리되는 컬렉션이 아닌 경우에는 반복문을 사용해서 요소에 하나씩 접근할 수 없기 때문에
* 인덱스를 사용하지 않고도 반복문을 사용하기 위한 목록을 만들어주는 역할이라고 보면 된다.
* descendingIterator() - 내림차순
*
* hasNext() : 다음 요소를 갖고 있는 경우 true, 더 이상 요소가 없는 경우 false를 반환
* next() : 다음요소를 반환
* */
Iterator<String> dIter = ((LinkedList<String>)stringList).descendingIterator();
while(dIter.hasNext()) {
System.out.println(dIter.next());
}
// orange
// mango
// grape
// banana
// apple
/* 한번 출력한 뒤엔 다시 출력할 수 없다. */
// while(dIter.hasNext()) {
// System.out.println(dIter.next());
// }
//
/* 역순으로 정렬 된 결과를 저장하기 위해서는 새로운 ArrayList를 만들어
* 저장 해 두면 된다.
* */
List<String> descList = new ArrayList<>();
while(dIter.hasNext()) {
descList.add(dIter.next());
}
System.out.println("descList : " + descList);
}
}
Application2
import java.util.ArrayList;
import java.util.Comparator;
import java.util.List;
import com.greedy.section01.list.comparator.AscendingPrice;
import com.greedy.section01.list.dto.BookDTO;
public class Application2 {
public static void main(String[] args) {
/* 여러 권의 책 목록을 관리할 ArrayList 인스턴스 생성 */
List<BookDTO> bookList = new ArrayList<>();
/* 도서 정보 추가, BookDTO 타입만 받아야 하기때문에 String 타입으로 작성할 수 없다. */
bookList.add(new BookDTO(1, "홍길동전", "허균", 50000));
bookList.add(new BookDTO(2, "목민심서", "정약용", 30000));
bookList.add(new BookDTO(3, "동의보감", "허준", 40000));
bookList.add(new BookDTO(4, "삼국사기", "김부식", 46000));
bookList.add(new BookDTO(5, "삼국유사", "일연", 58000));
/* 정렬 전 책 리스트 출력 */
for(BookDTO book : bookList) {
System.out.println(book);
}
// BookDTO [number=1, title=홍길동전, author=허균, price=50000]
// BookDTO [number=2, title=목민심서, author=정약용, price=30000]
// BookDTO [number=3, title=동의보감, author=허준, price=40000]
// BookDTO [number=4, title=삼국사기, author=김부식, price=46000]
// BookDTO [number=5, title=삼국유사, author=일연, price=58000]
/* 제네릭의 타입 제한에 의해 Comparable 타입을 가지고 있는 경우에만
* sort가 가능하다. 즉, 사전에 기준이 필요하다. */
// Collections.sort(bookList); // 정렬되지 않는다.
/* 가격 순으로 오름차순 정렬 - AscendingPrice 추가 */
/* Comparator 인터페이스를 상속받아 정렬 기준을 정해준 뒤
* List의 sort() 메소드의 인자로 정렬 기준이 되는 인터페이스를 넣어주게 되면
* 내부적으로 우리가 오버라이딩 한 메소드가 동작하여 그것을 정렬기준으로 삼는다.
* */
bookList.sort(new AscendingPrice());
System.out.println("가격 오름차순 정렬 -------------------");
for(BookDTO book : bookList) {
System.out.println(book);
}
// 가격 오름차순 정렬 -------------------
// BookDTO [number=2, title=목민심서, author=정약용, price=30000]
// BookDTO [number=3, title=동의보감, author=허준, price=40000]
// BookDTO [number=4, title=삼국사기, author=김부식, price=46000]
// BookDTO [number=1, title=홍길동전, author=허균, price=50000]
// BookDTO [number=5, title=삼국유사, author=일연, price=58000]
/* 인터페이스를 구현할 클래스를 재사용 하는 경우 AscendingPrice 클래스처럼 작성하면 되지만
* '한번만 사용'하기 위해서는 조금 더 간편한 방법을 이용할 수 있다.
* 즉, 재사용하지않는 목적에 한 해서 익명 클래스를 이용한 방법이다.
*
* 익명클래스는 뒤에 {}를 만들어서 마치 Comparator 인터페이스를 상속받은 클래스인데
* 이름이 없다고 생각하고 사용하는 것이다.
*
* */
bookList.sort(new Comparator<BookDTO> () {
@Override
public int compare(BookDTO o1, BookDTO o2) {
/* 여기에 내림차순 정렬 조건을 넣어주면 된다.
* 아까와는 반대로 오름차순 정렬 된 상태인 경우 순서를 바꿔야한다.
* 양수를 반환해서 순서를 바꾸라는 플래스로 이용했었다.
*
* 양수값이 반환되면 바꿀필요없으며, 음수가 반환되면 순서를 바꾸고,
* 같을시 0반환
* */
return o2.getPrice() - o1.getPrice();
}
});
System.out.println("가격 내림차순 정렬 -------------------");
for(BookDTO book : bookList) {
System.out.println(book);
}
// BookDTO [number=5, title=삼국유사, author=일연, price=58000]
// BookDTO [number=1, title=홍길동전, author=허균, price=50000]
// BookDTO [number=4, title=삼국사기, author=김부식, price=46000]
// BookDTO [number=3, title=동의보감, author=허준, price=40000]
// BookDTO [number=2, title=목민심서, author=정약용, price=30000]
/* 제목 순 오름차순 정렬 */
bookList.sort(new Comparator<BookDTO>() {
@Override
public int compare(BookDTO o1, BookDTO o2) {
/* 문자열은 대소비교를 할 수 없다.
* 문자 배열로 변경 후 인덱스 하나하나를 비교해서 어느 것이 더 큰 값인지 확인해야하는데
* String 클래스의compareTo() 메소드에서 이미 정의 해 놓았다.
* */
/* 앞의 값이 더 작은 경우 음수 반환,
* 같으면 0반환
* 앞의 값이 더 큰 경우 양수반환 (즉, 바꿔야 하는 경우) */
return o1.getTitle().compareTo(o2.getTitle());
}
});
System.out.println("제목 오름차순 정렬 -------------------");
for(BookDTO book : bookList) {
System.out.println(book);
}
/* 제목 내림차순 정렬 */
bookList.sort(new Comparator<BookDTO> () {
@Override
public int compare(BookDTO o1, BookDTO o2) {
// 위 오름차순 순서와 반대되는 값을 반환해야 한다.
// 값이 반전될 수 있게 하는 처리가 필요하다.
return o2.getTitle().compareTo(o1.getTitle());
}
});
System.out.println("제목 내림차순 정렬 -------------------");
for(BookDTO book : bookList) {
System.out.println(book);
}
// 제목 내림차순 정렬 -------------------
// BookDTO [number=1, title=홍길동전, author=허균, price=50000]
// BookDTO [number=5, title=삼국유사, author=일연, price=58000]
// BookDTO [number=4, title=삼국사기, author=김부식, price=46000]
// BookDTO [number=2, title=목민심서, author=정약용, price=30000]
// BookDTO [number=3, title=동의보감, author=허준, price=40000]
}
/* Vector의 경우 스레드 동기화 처리가 된다는 점만 다르고 ArrayList와 동일하게 동작한다.
* 그래서 따로 작성하지 않을 것이다.
* JDK 1.0부터 사용하긴 했지만 하위 호환을 위해 남겨놓았고 성능 문제로 현재는 사용하지 않는다.
* 가급적이면 ArrayList를 사용하면 된다. */
}
BookDTO
public class BookDTO {
/* 필드 */
private int number;
private String title;
private String author;
private int price;
/* 필드뒤에오는건 기본 생성자 */
public BookDTO() {}
/* 필드뒤에오는건 매개변수를 가지는 생성자 */
public BookDTO(int number, String title, String author, int price) {
super();
this.number = number;
this.title = title;
this.author = author;
this.price = price;
}
/* 게터 세터 */
public int getNumber() {
return number;
}
public void setNumber(int number) {
this.number = number;
}
public String getTitle() {
return title;
}
public void setTitle(String title) {
this.title = title;
}
public String getAuthor() {
return author;
}
public void setAuthor(String author) {
this.author = author;
}
public int getPrice() {
return price;
}
public void setPrice(int price) {
this.price = price;
}
/* toString */
@Override
public String toString() {
return "BookDTO [number=" + number + ", title=" + title + ", author=" + author + ", price=" + price + "]";
}
}
AscendingPrice implements Comparator<BookDTO>
import java.util.Comparator;
import com.greedy.section01.list.dto.BookDTO;
public class AscendingPrice implements Comparator<BookDTO> {
/* 목적 : 정렬기준 설정해주기 */
// @Override
// public int compare(Object o1, Object o2) {
// // 오브젝트 타입에서는 접근 불가능함, 다운캐스팅 필요
// return 0;
// }
@Override
public int compare(BookDTO o1, BookDTO o2) { // 임포트 필요
// TODO Auto-generated method stub
/* sort()에서 내부적으로 사용하는 메소드이다.
* 인터페이스를 상속받아서 메소드 오버라이딩하는 것을 강제화 해놓았다.
* */
/* 정렬 기준/판단기준 설정, 비교 대상 두 인스턴스의 가격이 오름차순 정렬이 되기 위해서는
* 앞의 가격이 더 작은 가격이어야 한다.
* 만약, 뒤의 가격이 더 작은 경우 두 인스턴스의 순서를 바꿔야 한다.
* 그 때 두 값을 바꾸라는 신호로 양수를 보내주게 되면 정렬 시 순서를 바꾸는 조건으로 사용 된다.
* (음수는 바꾸지X)
* */
/* 양수, 음수 형태로 두 비교 값이 순서를 바꿔야 하는지를 알려주기 위한 용도의 변수 */
int result = 0;
if (o1.getPrice() > o2.getPrice()) {
/* 오름차순을 위해 순서를 바꿔야 하는 경우 양수반환 */
result = 1;
} else if (o1.getPrice() < o2.getPrice()) {
/* 이미 오름차순 정렬로 되어 있는 경우 음수를 반환 */
result = -1;
} else {
/* 두 값이 같은 경우 0을 반환*/
result = 0;
return 0;
}
return result;
/* 정렬의 기준을 작성 해 놓은것이다. 상황에 따라 1, -1, 0이 반환되게끔. */
}
}
Application3
import java.util.LinkedList;
import java.util.List;
public class Application3 {
public static void main(String[] args) {
/* LinkedList
* ArrayList가 배열을 이용해서 발생할 수 있는 성능적인 단점을 보환하고자 고안되었다.
* 내부는 이중 연결리스트로 구현되어 있다.
*
* 단일 연결 리스트
* : 저장한 요소가 순서를 유지하지 않고 저장되지만 이러한 요소들 사이를 링크로 연결하여
* 구성하며 마치 연결 된 리스트 형태인 것처럼 만든 자료구조이다.
* 요소의 저장과 삭제 시 다음 요소를 가리키는 참조 링크만 변경하면 되기 때문에
* 요소의 저장과 삭제가 빈번히 일어나는 경우 ArrayList보다 성능면에서 우수하다.
* 단, 다음값만 가지고 있기 때문에 이전값으로 역순이동 하려는 경우엔 어려움을 겪어
* 이러한 단점을 보완하기위해 이중연결 리스트가 고안되었다.
*
* 이중 연결 리스트(LinkedList)
* : 단일 연결 리스트는 다음 요소만 링크하는 반면 이중 연결 리스트는 이전 요소도 링크하여
* 이전 요소로 접근하기 쉽게 고안된 자료구조이다.
*
*
* 하지만 내부적으로 요소를 저장하는 방법에 차이가 있는것이다.
* 각 컬렉션 프레임 뭐크 클래스들의 특징을 파악하고 그에따라 적합한 자료구조를 구현한
* 클래스를 선택하는 것이 좋다.
*
*
*
* */
/* LinkedList 인스턴스 생성 */
List<String> linkedList = new LinkedList<>();
/* 요소를 추가할 때는 add를 이용한다. */
linkedList.add("apple");
linkedList.add("banana");
linkedList.add("orange");
linkedList.add("mango");
linkedList.add("grape");
/* 저장된 요소의 갯수는 size() 메소드를 이용한다. */
System.out.println(linkedList.size());
// 콘솔창 출력 : 5
/* for문과 size()를 이용해서 반복문을 활용할 수도 있다.
* 요소를 꺼내올 때는 get()을 사용하며,
* 인자로 전달하는 정수는 인덱스처럼 사용하면 된다.
* */
for (int i = 0; i < linkedList.size(); i++) {
System.out.println(i + " : " + linkedList.get(i));
}
// 0 : apple
// 1 : banana
// 2 : orange
// 3 : mango
// 4 : grape
/* 요소를 제거할 때는 remove 메소드를 이용하며 인덱스를 활용한다. */
linkedList.remove(1);
/* 향상된 for문도 사용가능하다. */
for (String s: linkedList) {
System.out.println(s);
}
// apple
// orange
// mango
// grape
/* set() 메소드를 이용해서 요소를 수정할 수도 있다. */
linkedList.set(0, "pineapple");
/* toString 메소드가 오버라이딩 돼 있어서 모든 요소 정보를 쉽게 볼 수 있다. */
System.out.println(linkedList);
// 출력: [pineapple, orange, mango, grape]
/* isEmpty() 메소드를 이용해서 list 가 비어있는지 확인할 수 있다. */
System.out.println(linkedList.isEmpty());
// false : 비어있지 않으므로 출력
/* 리스트 내 요소를 모두 제거하는 clear() 메소드를 이용할 수도 있다. */
linkedList.clear();
System.out.println(linkedList.isEmpty());
// true : clear() 메소드로 비웠으므로 true
}
}
Stack
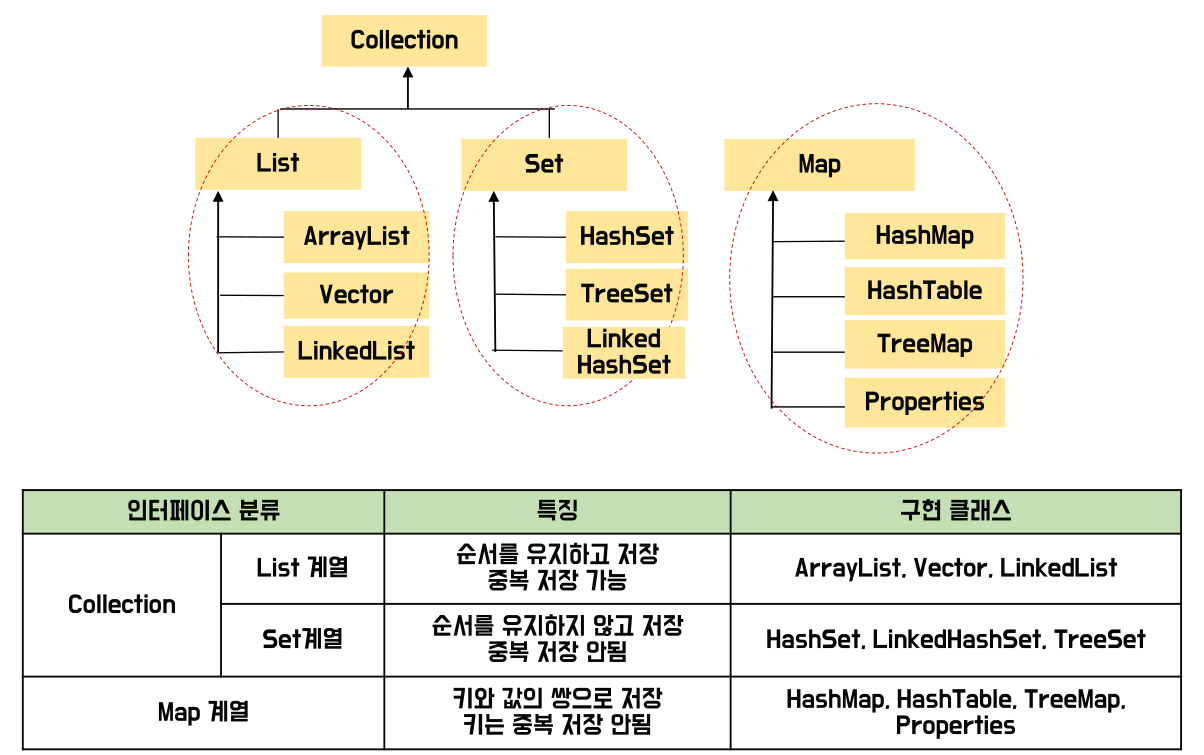
stack은 List에서 파생되었다.
stack은 제한적으로 접근할 수 있는 나열 구조로 데이터를 저장
쌓아나간다고 생각, 넣을때는 바닥부터, 꺼낼때는 위에 쌓인 것 부터
후임선출(LIFO - Last Input First Out)방식의 자료 구조 - 마지막에 넣은것이 가장 처음 나온다
Application4
import java.util.Stack;
public class Application4 {
public static void main(String[] args) {
/* Stack */
/* Stack은 리스트 계열 클래스의 Vector 클래스를 상속받아 구현되었다.
* 스택메모리 구조는 선형 메모리 공간에 데이터를 저장하며
* 후입선출 (LIFO - Last Input First Out) 방식의 자료구조라 부른다.
* */
/* Stack 인스턴스 생성 */
Stack<Integer> integerStack = new Stack<>(); // 임포트
/* Stack에 값을 넣을 때는 push() 메소드를 이용한다.
* 벡터의 기능을 상속받았으므로 add() 이용이 가능하긴 하지만
* push()를 이용하는 것이 좋다.
* */
integerStack.push(1); // 오토 박싱이 되므로 그냥 인트값을 넣어준다.
integerStack.push(2);
integerStack.push(3);
integerStack.push(4);
integerStack.push(5);
/* 값을 출력할때는 순서대로 나온다. */
System.out.println(integerStack);
// [1, 2, 3, 4, 5]
/* Stack의 Search()메소드는 위에서부터의 순번을 찾아오는데,
* 스택의 자료구조는 아래서부터 쌓이는 방식이라고 했다. */
/* 스택에서 요소를 찾을때 search를 이용할 수 있따.
* 인덱스가 아닌 위에서부터의 순번을 의미한다.
* 또한 가장 상단의 위치가 0이 아닌 1부터 시작한다. */
System.out.println(integerStack.search(5));
// 콘솔 출력: 1
/* Stack에서 값을 꺼내는 메소드는 크게 2가지로 볼 수 있다.
* peek(): 해당 스택의 가장 마지막에 (상단에 있는) 요소반환
* pop() : 해당 스택의 가장 마지막에 있는 (상단에 있는) 요소 반환 후
* 반환했던 요소를 제거
* */
System.out.println("peek() : " + integerStack.peek());
System.out.println(integerStack);
// peek() : 5
// [1, 2, 3, 4, 5]
System.out.println("pop() : " + integerStack.pop());
System.out.println(integerStack);
// pop() : 5
// [1, 2, 3, 4]
/* pop은 꺼내면서 요소를 제거학 때문에 스택이 비어있는 경우 에러가 발생할 수 있다. */
System.out.println("pop() : " + integerStack.pop());
System.out.println("pop() : " + integerStack.pop());
System.out.println("pop() : " + integerStack.pop());
System.out.println("pop() : " + integerStack.pop());
System.out.println("pop() : " + integerStack.pop());
// 모두 출력+ 제거후 더 이상 반환할 요소가 없을때 에러를 발생시킨다.
// java.util.EmptyStackException
}
}
Queue
queue
queue는 선형 메모리 공간에 데이터를 저장
선입선출(FIFO - First Input First Out)방식의 자료구조
Application5
import java.util.*;
import java.util.LinkedList;
import java.util.Queue;
public class Application5 {
public static void main(String[] args) {
/* Queue */
/* Queue는 선형 메모리 공간에 데이터를 저장하는
* 선입 선출(FIFO - First Input First Out) 방식의 자료구조이다.
* Queue 인터페이스를 상속받는 하위 인터페이스들은
* Deque, BlockingQueue, TransferQueue 등 다양하지만
* 대부분의 큐는 LinkedList를 이용한다.
* */
/* Queue자체로는 인터페이스이기 때문에 인스턴스 생성이 불가능하다. */
// Queue<String> que = new Queue<>();
// 생설할 수는 없는데 그 이유는 인터페이스 이기 때문
/* LinkedList로 인스턴스 생성 */
Queue<String> que = new LinkedList<>();
/* 큐에 데이터를 넣을때에는 offer() 를 이용한다. */
que.offer("first");
que.offer("second");
que.offer("third");
que.offer("fourth");
que.offer("fifth");
System.out.println(que);
// [first, second, third, fourth, fifth]
/* 큐에서 데이터를 꺼낼때는 2가지 메소드가 있다.
* peek() : 해당 큐의 가장 앞에있는 요소 (먼저들어온 요소)를 반환한다.
* poll() : 해당 큐의 가장 앞에있는 요소 (먼저들어온 요소)를 반환하고 반환한 요소를 제거한다.
* */
System.out.println("peek() : " + que.peek());
System.out.println(que);
// peek() : first
// [first, second, third, fourth, fifth]
System.out.println("poll() : " + que.poll());
System.out.println(que);
// poll() : first
// [second, third, fourth, fifth] // 출력된 데이터는 제거되었다.
}
}
Set
set이란?
저장 순서가 유지되지 않고, 중복 인스턴스도 저장하지 못하게 하는 자료구조
null값도 중복하지 않게 하나의 null만 저장 가능
구현 클래스 : HashSet, LinkedHashSet, TreeSet
Set 계열 주요 메소드
Iterator
컬렉션에 저장된 요소를 접근하는데 사용되는 인터페이스
List와 Set계열에서만 사용
Map의 경우 사용할 수 없다. Map의 경우엔 Set 또는 List'화' 시켜서(바꿔서) iterator()를 사용
HashSet
Set에 인스턴스를 저장할 때 hash함수를 사용하여 처리 속도가 빠름
동일 인스턴스 뿐 아니라 동등 인스턴스도 중복하여 저장하지 않음
동일 : 완전히 같은 인스턴스 동등 : 다른 인스턴스이지만 특정한 기준들의 속성 값이 같음
LinkedHashSet
HashSet과 거의 동일하지만 Set에 추가되는 순서를 유지함
TreeSet
이진 트리를 기반으로 한 Set컬렉션으로, 왼쪽과 오른쪽 자식 노드를 참조하기 위한 두 개의 변수로 구성
추가된 값이 기존 값(5)을 기준으로 큰지(7) 작은지(3) 판단하여 정렬된 형태(3-5-7)로 저장한다, 즉 기존값 기준 더 작은 것은 왼쪽에, 더 큰값은 오른쪽에
Applicaion1
import java.util.HashSet;
import java.util.Iterator;
public class Applicaion1 {
public static void main(String[] args) {
/* Set 인터페이스를 구현한 Set 컬렉션 클래스의 특징
* 1. 요소의 저장 순서를 유지하지 않는다.
* 2. 같은 요소의 중복 저장을 허용하지 않는다.
* (null값도 중복되지않아 하나의 null만 저장한다.)
*
* */
/* HashSet 클래스
* Set 컬렉션 클래스에서 가장 많이 사용 되는 클래스 중 하나이다.
* JDK 1.2 부터 제공되고 있으며 해시 알고리즘을 사용하여 검색 속도가
* 빠르다는 장점을 가진다.
*
* */
/* HashSet 인스턴스 생성 */
HashSet<String> hset = new HashSet<>();
/* 다형성을 적용하여 상위 인터페이스를 타입으로 사용가능 */
// Set hset2 = new HashSet();
// Collection hset3 = new HashSet();
hset.add(new String("java"));
hset.add(new String("oracle"));
hset.add(new String("jdbc"));
hset.add(new String("html"));
hset.add(new String("css"));
/* toString 이 오버라이딩 되어 있다.
* 저장 순서 유지 안됨*/
System.out.println(hset);
// [css, java, oracle, jdbc, html]
//저장한 순서와 담겨있는 순서는 같지않다.
/* 중복 데이터 저장 허용 안됨 */
hset.add(new String("java"));
System.out.println(hset);
// [css, java, oracle, jdbc, html]
// 원래 저장돼있기때문에 추가 저장은 안됨
System.out.println("저장 된 객체 수 : " + hset.size());
// 저장 된 객체 수 : 5
System.out.println("포함 여부 확인 : " + hset.contains(new String("oracle")));
// 포함 여부 확인 : true
/* 저장 된 객체를 하나씩 꺼내는 기능이 없음 */
/* 반복문을 이용한 연속 처리 하는 방법 */
/* 1. toArray()로 배열로 변경한 뒤 for loop 사용 */
Object[] arr = hset.toArray();
for (int i = 0; i < arr.length; i++) {
System.out.println(i + " : " + arr[i]);
}
// 0 : css
// 1 : java
// 2 : oracle
// 3 : jdbc
// 4 : html
/* 2. iterator()로 목록 만들어 연속 처리 */
Iterator<String> iter = hset.iterator();
while(iter.hasNext()) {
System.out.println(iter.next());
}
// css
// java
// oracle
// jdbc
// html
/* 지우는 방법 */
hset.clear();
System.out.println("empty? : " + hset.isEmpty());
// empty? : true
}
}
Application2
import java.util.LinkedHashSet;
import java.util.TreeSet;
public class Application2 {
public static void main(String[] args) {
/* LinkedHashSet 클래스 */
/* HashSet이 가지는 기능을 모두 가지고 있고
* 추가적으로 저장 순서를 유지하는 특징을 가지고 있다.
* JDK 1.4부터 제공하고 있다. */
LinkedHashSet<String> lhset = new LinkedHashSet<>();
lhset.add("java");
lhset.add("oracle");
lhset.add("jdbc");
lhset.add("html");
lhset.add("css");
/* 저장된 순서를 유지하고있다. */
System.out.println("lhset : " + lhset);
// lhset : [java, oracle, jdbc, html, css]
/* 만들어진 링크드해쉬셋을 가지고 트리셋으로 객체를 생성하면
* 같은 타입의 객체를 자동으로 비굑하여 오름차순으로 정렬한다.
* */
TreeSet<String> tset = new TreeSet<>(lhset);
System.out.println(tset);
// [css, html, java, jdbc, oracle]
}
}
Application3
import java.util.Iterator;
import java.util.Set;
import java.util.TreeSet;
public class Application3 {
public static void main(String[] args) {
/* TreeSet 클래스 */
/* TreeSet 클래스는 데이터가 정렬 된 상태로 저장 되는 이진 검색 트리의
* 형태로 요소를 저장한다.
* 이진 검색 트리는 데이터를 추가하거나 제거하는 등의 기본동작 시간이 매우 빠르다.
* jdk 1.2 부터 제공되고 있으며
* Set 인터페이스가 가지는 특징을 그대로 가지지만 정렬 된 상태를 유지한다는 것이
* 다른 점이다.
* */
TreeSet<String> tset = new TreeSet<>();
// Set<String> tset2 = new TressSet<>();
// 다형성을 이용하여 상위타입으로 선언하는 것도 가능하다.
tset.add("java");
tset.add("oracle");
tset.add("jdbc");
tset.add("html");
tset.add("css");
/* 자동 오름차순 정렬 */
System.out.println(tset);
// [css, html, java, jdbc, oracle]
/* 목록 만들어서 하나씩 대문자로 변경해서 출력처리 */
Iterator<String> iter = tset.iterator();
while(iter.hasNext()) {
System.out.println(iter.next().toUpperCase());
}
// CSS
// HTML
// JAVA
// JDBC
// ORACLE
/* 배열로 바꾸어 연속 처리하기 */
Object[] arr = tset.toArray();
for(Object obj : arr) {
System.out.println(((String)obj).toUpperCase());
}
// 그냥 오브젝트에서는 대문자변환이 불가능하므로
// 오브젝트를 참조형인 스트링으로 강제 타입 변환 해준다.
/* 로또번호 발생기 (TreeSet의 이용) */
Set<Integer> lotto = new TreeSet<>();
while(lotto.size() < 6) {
lotto.add((int)(Math.random() * 45) +1);
} // add가 중복을 막아줌, 정렬역시 treeset이 해주므로 정렬도 필요없음
System.out.println("lotto : " + lotto);
// lotto : [8, 11, 13, 34, 35, 43]
}
}